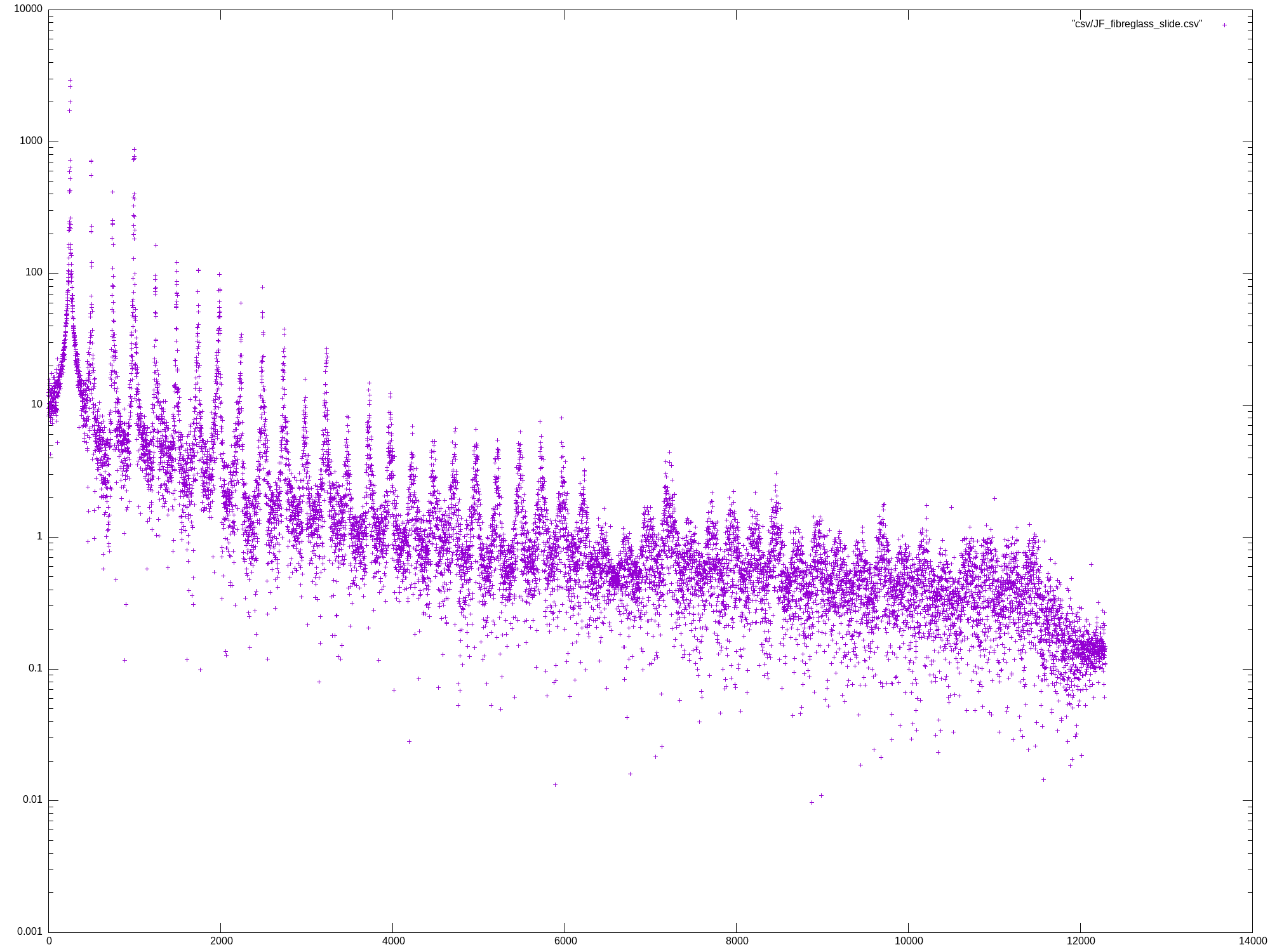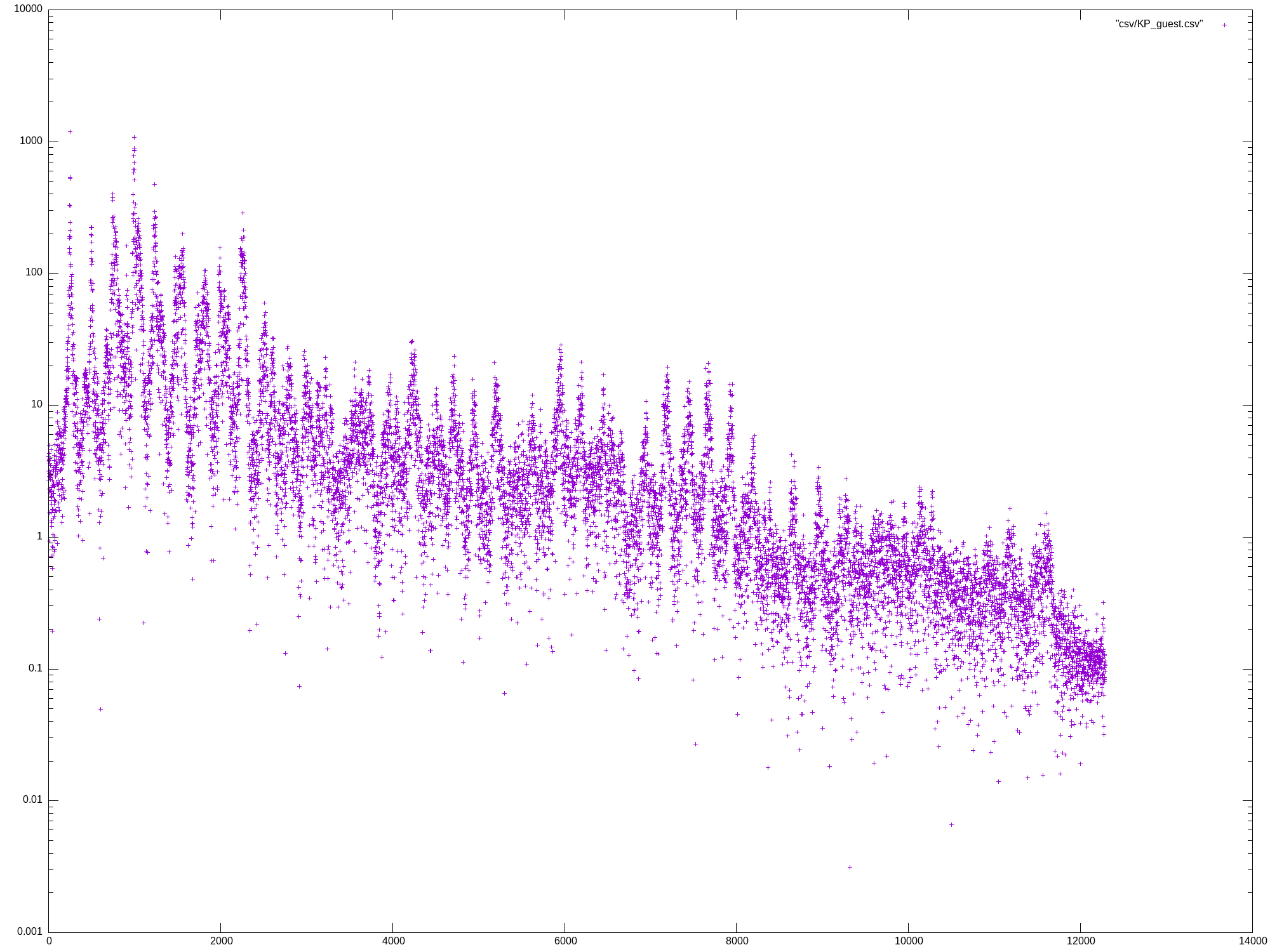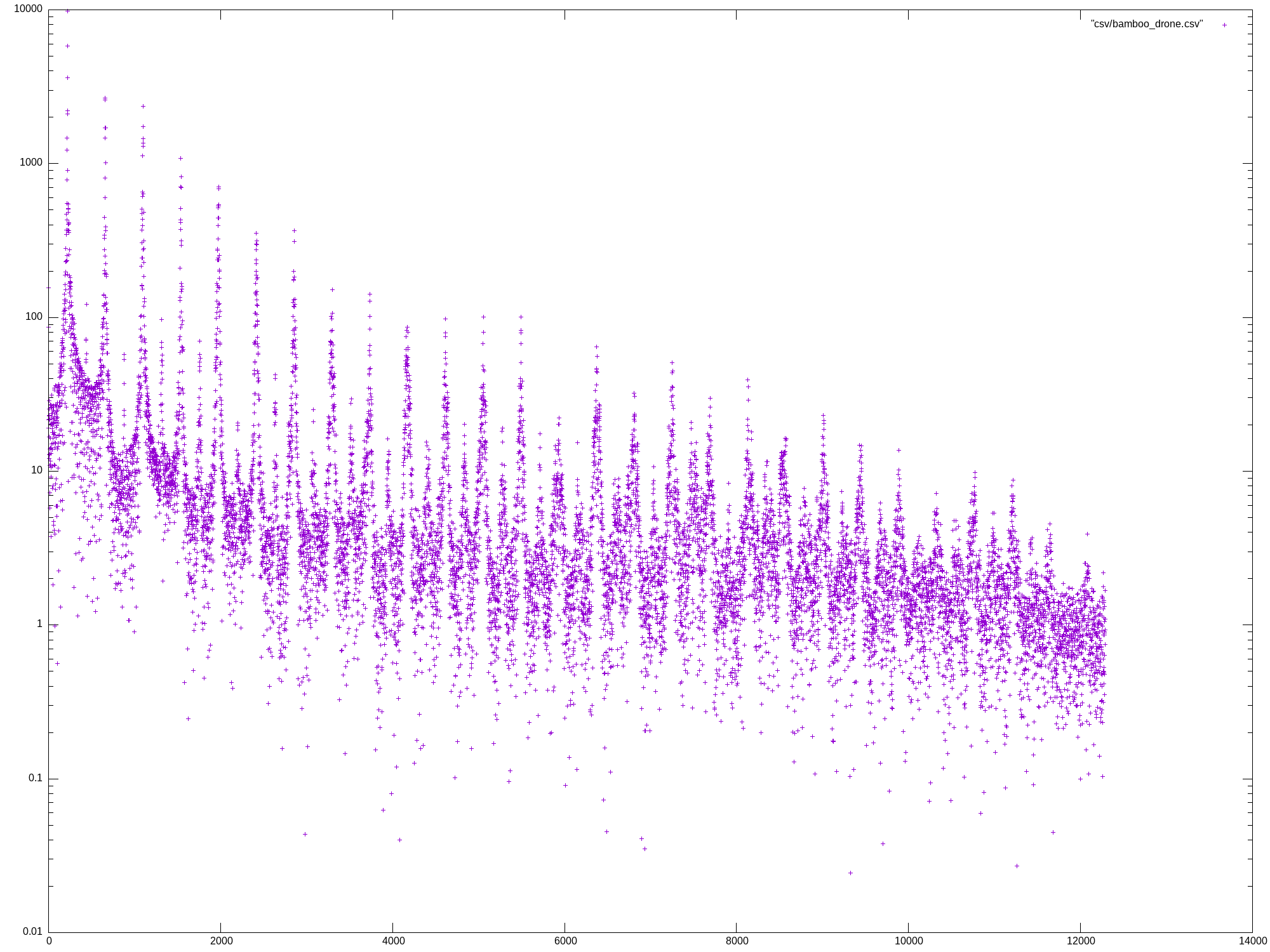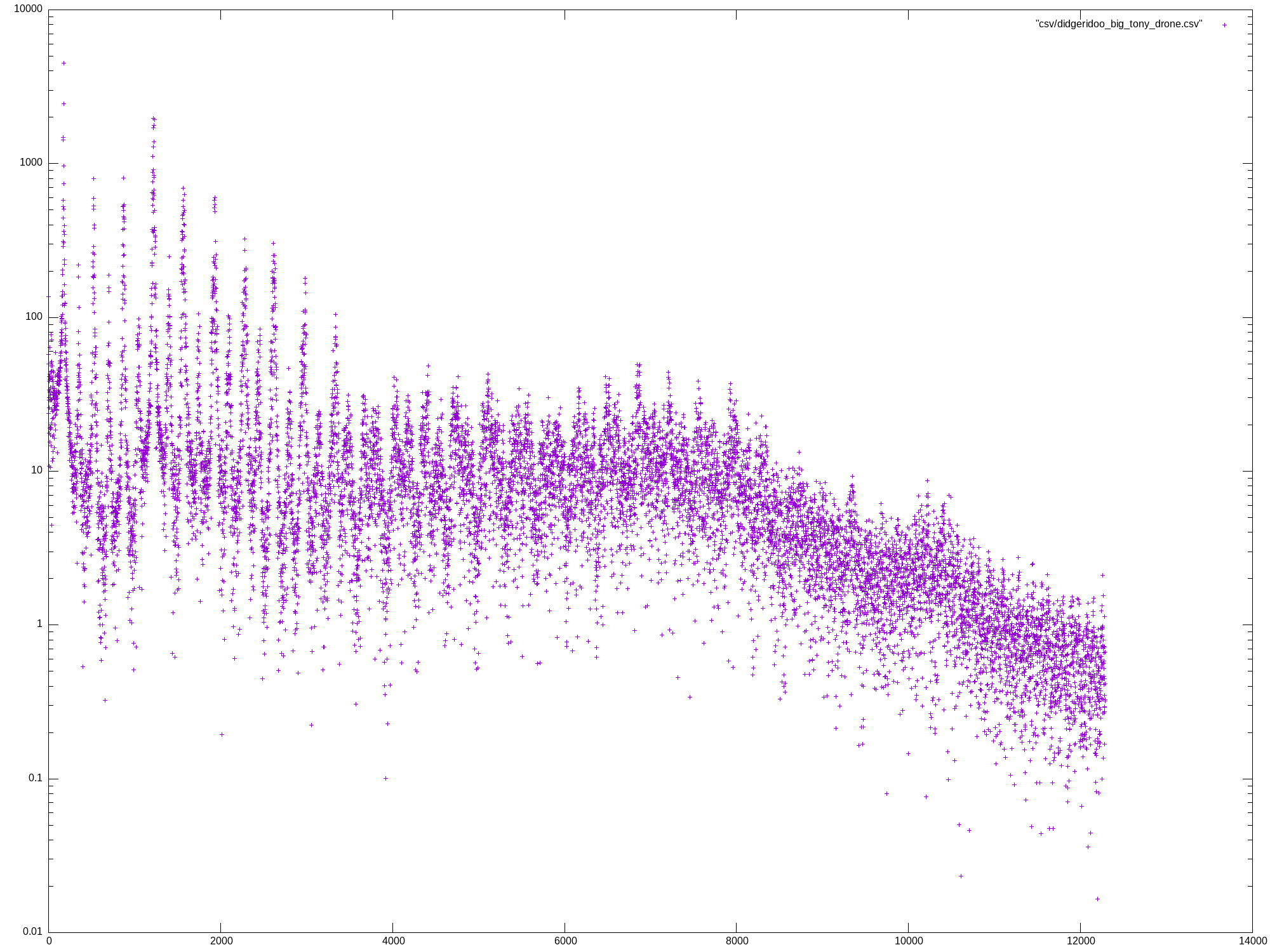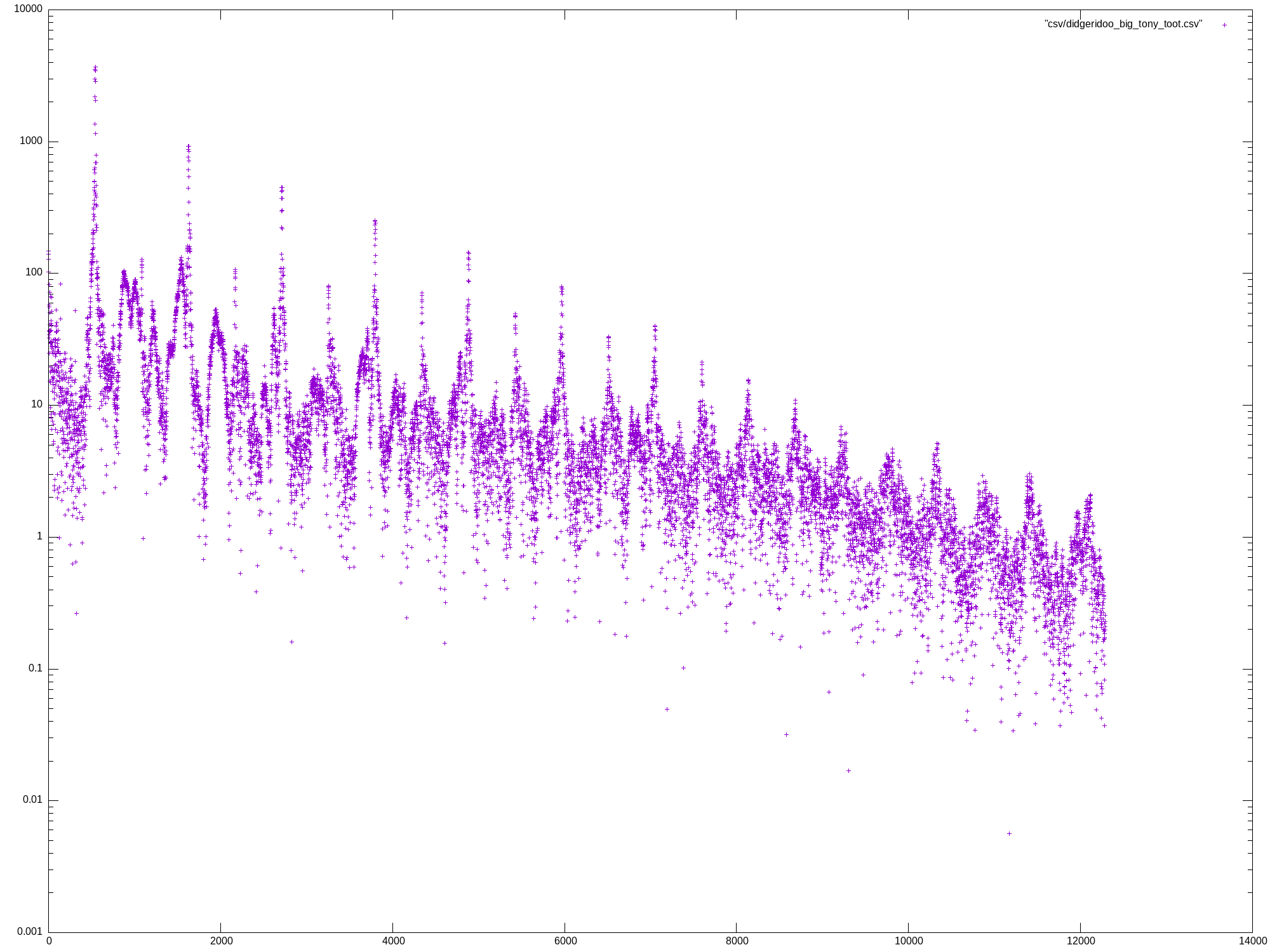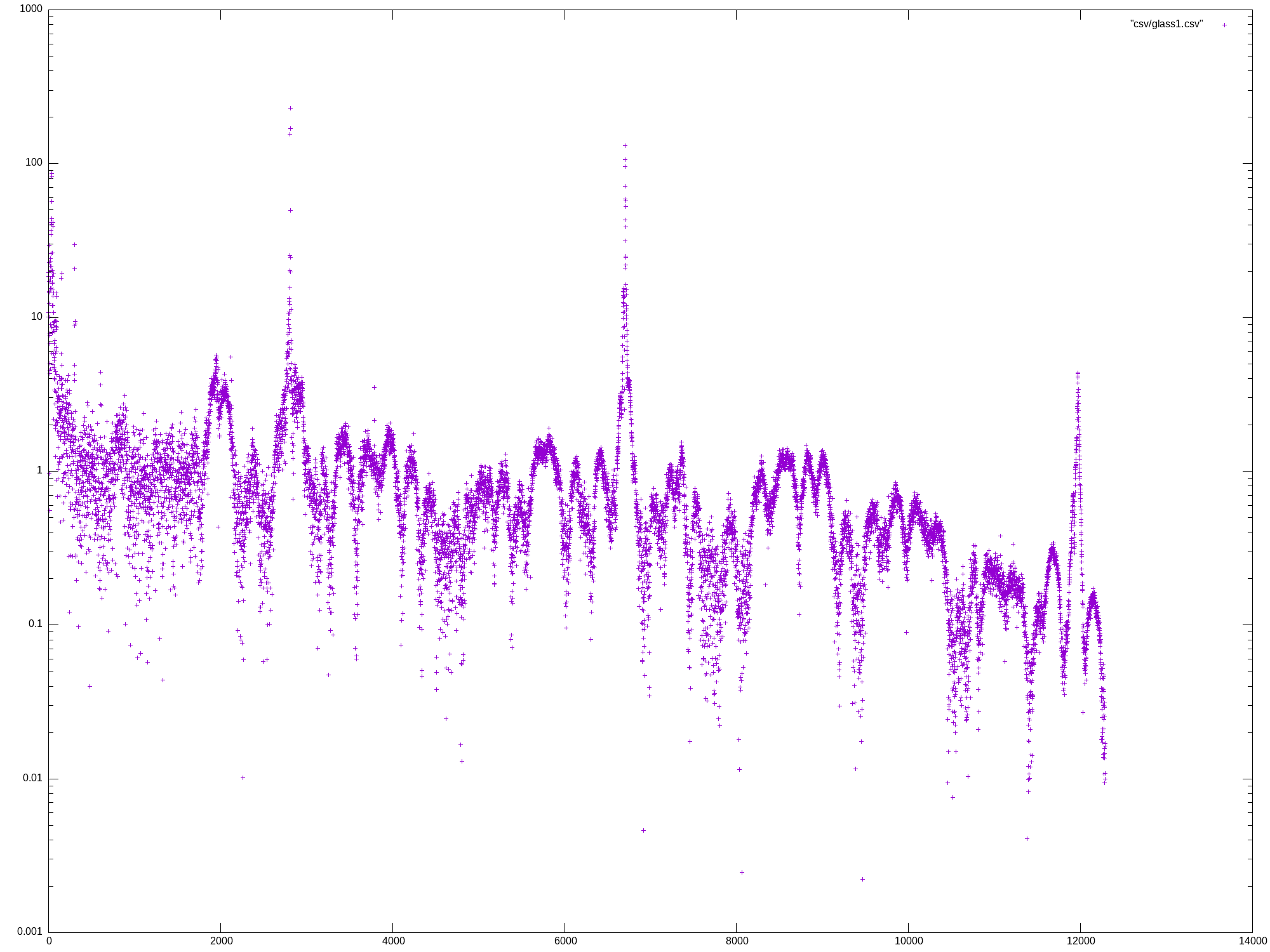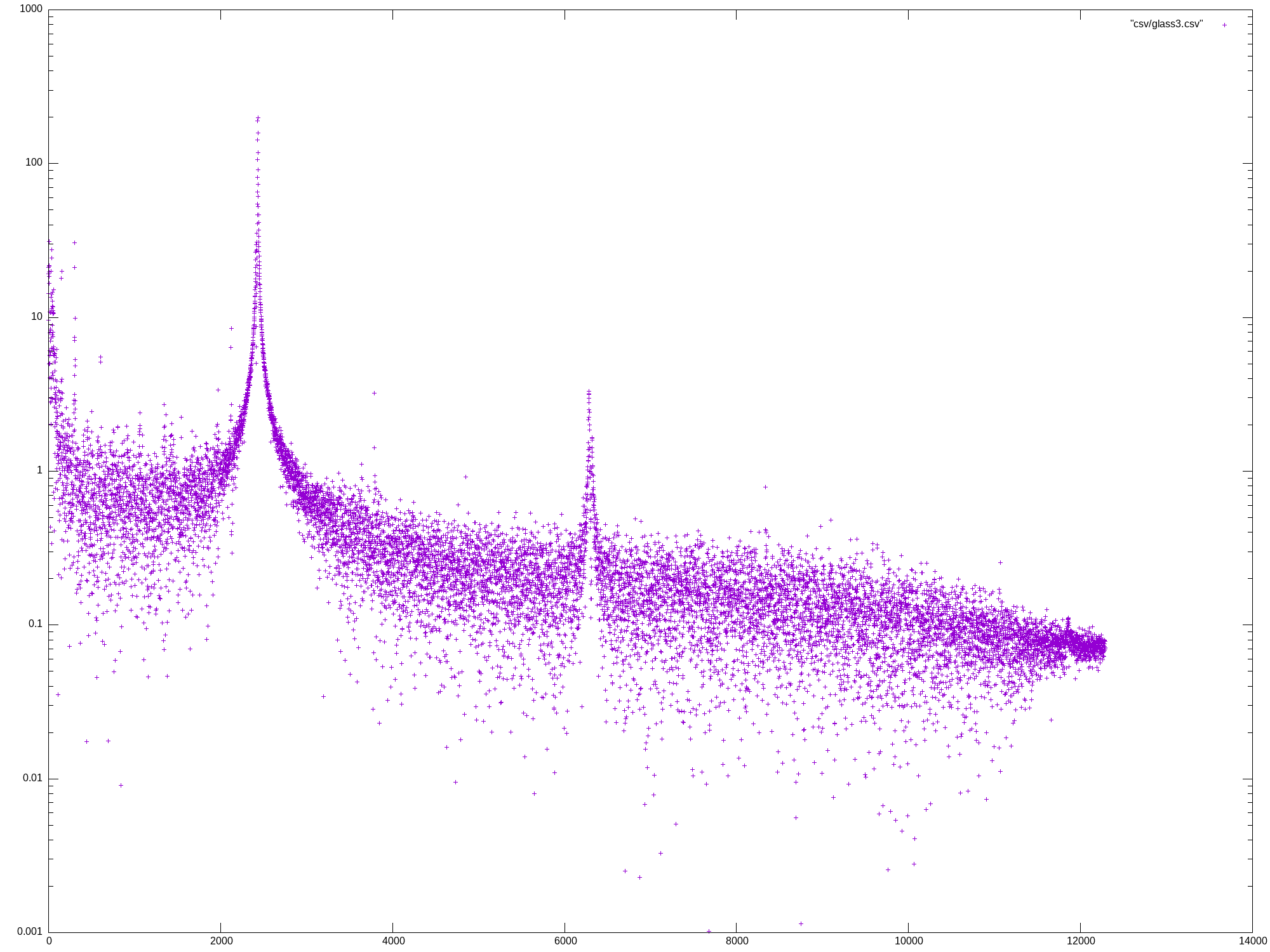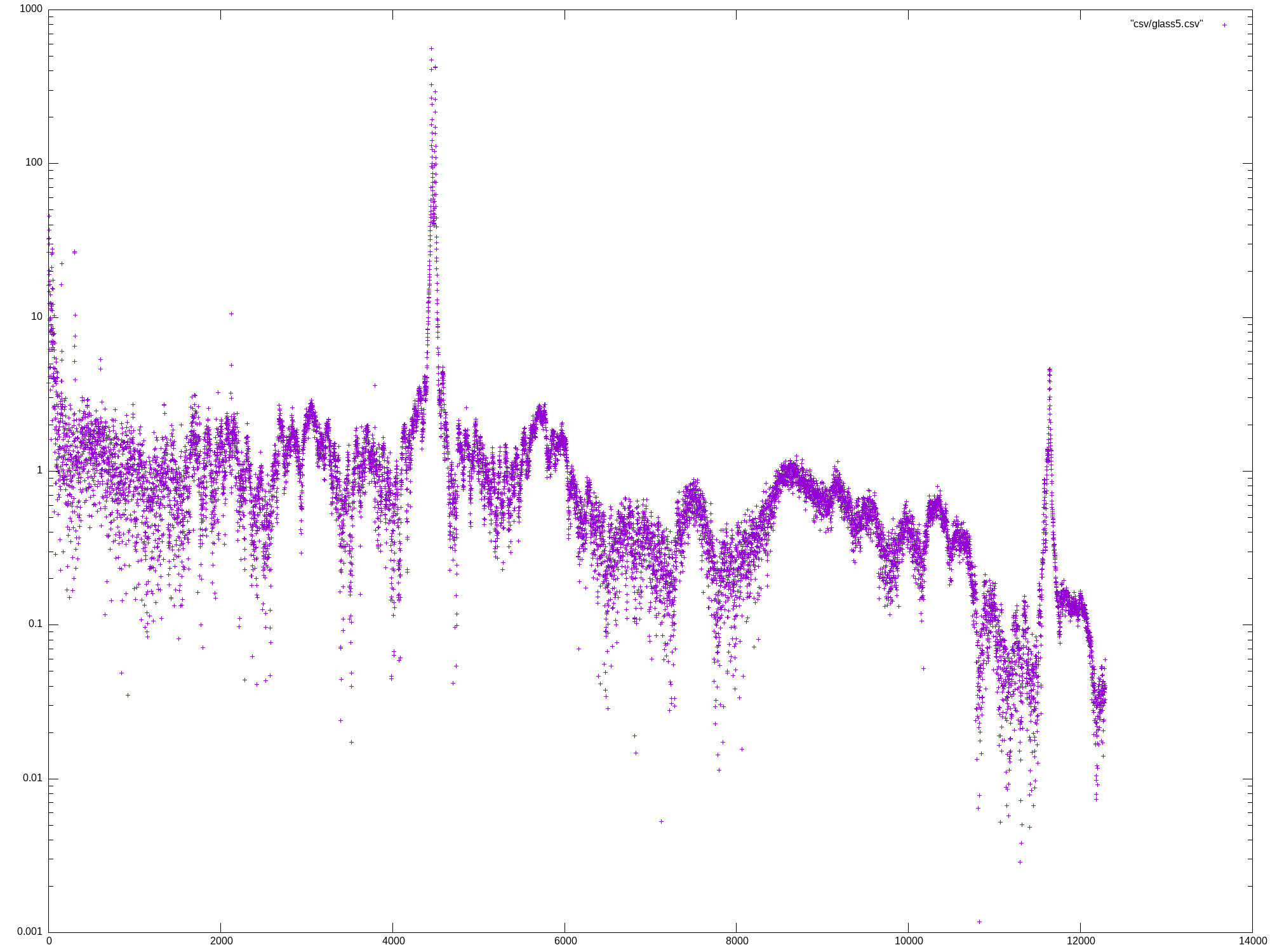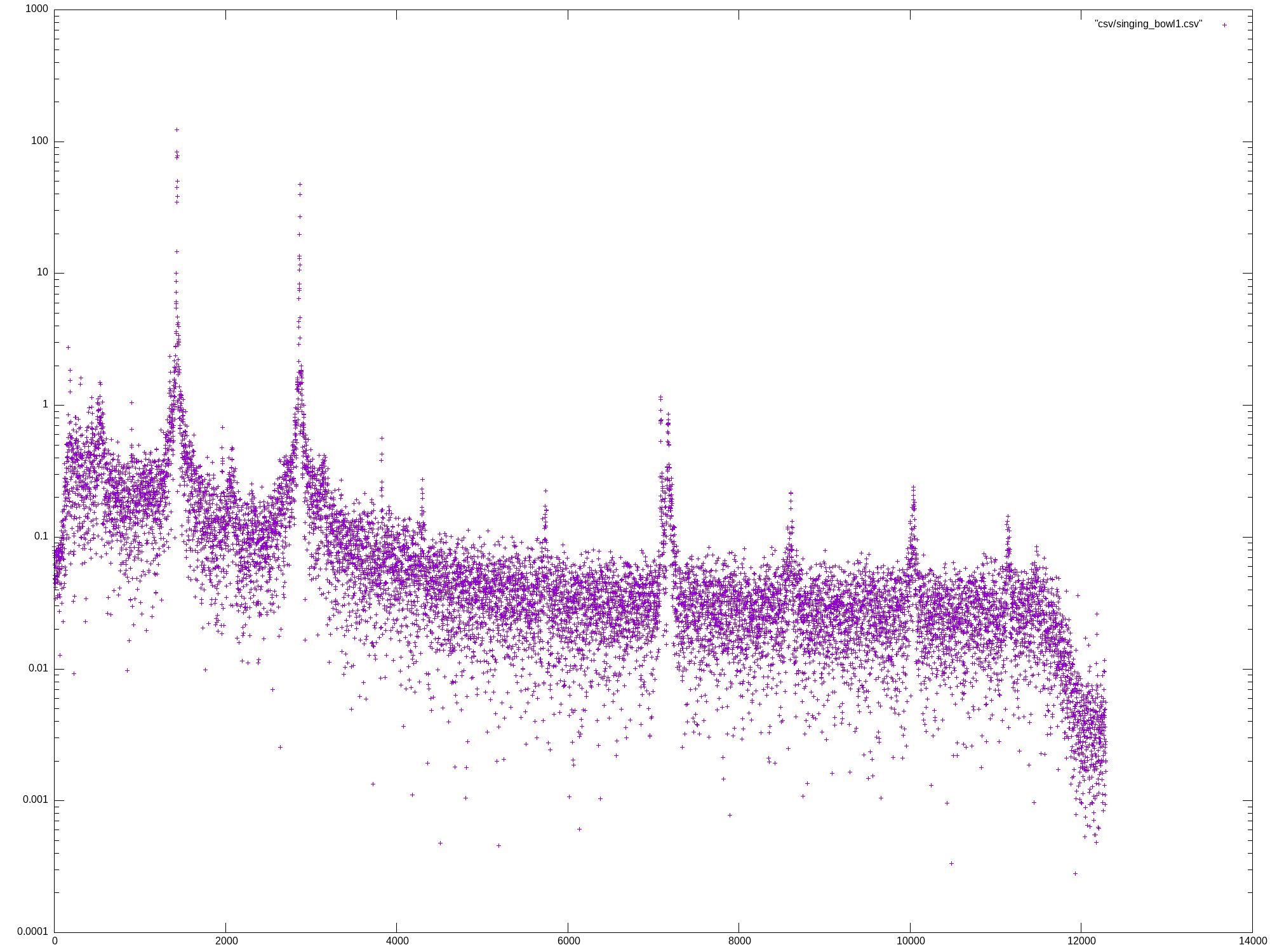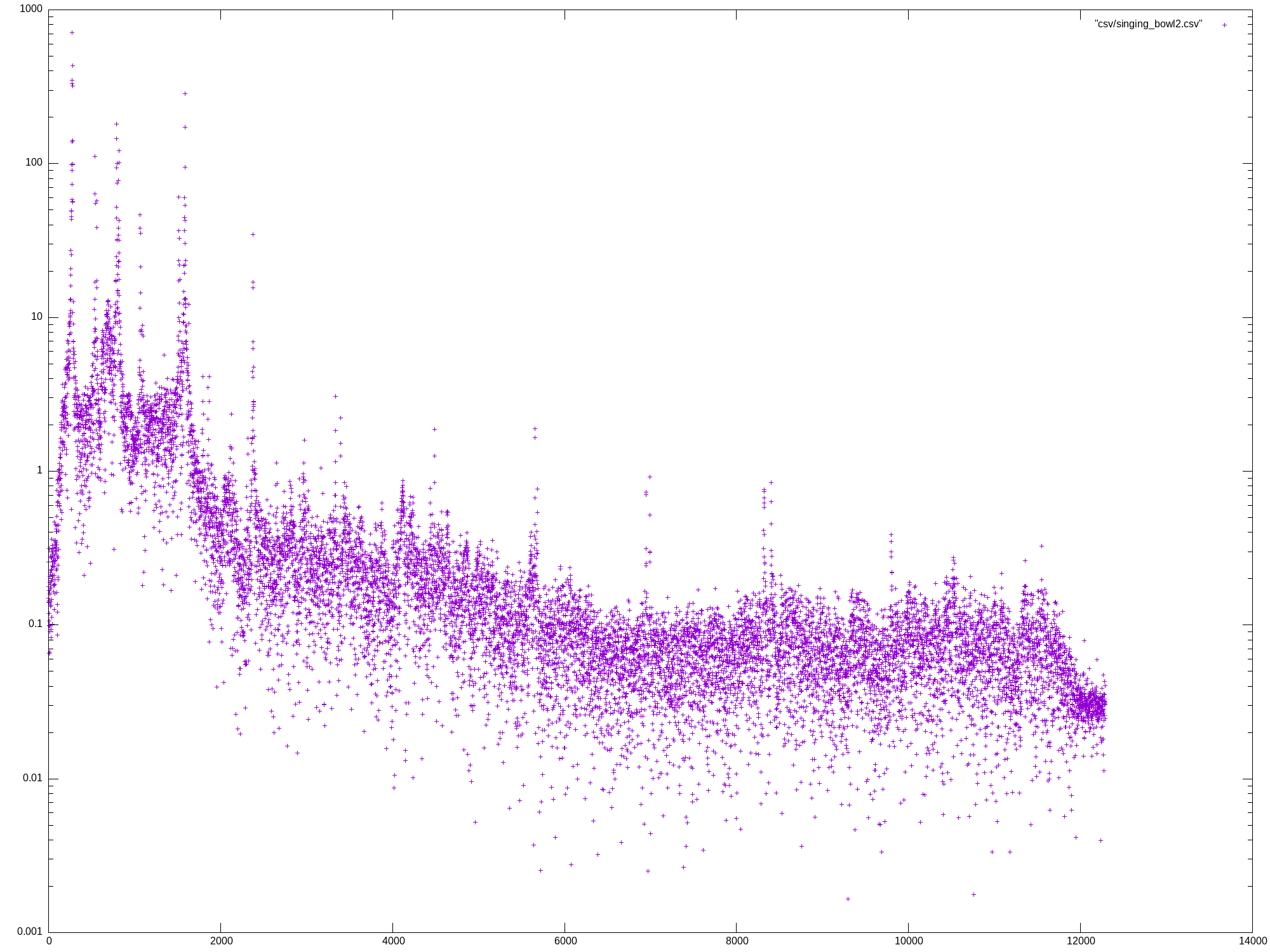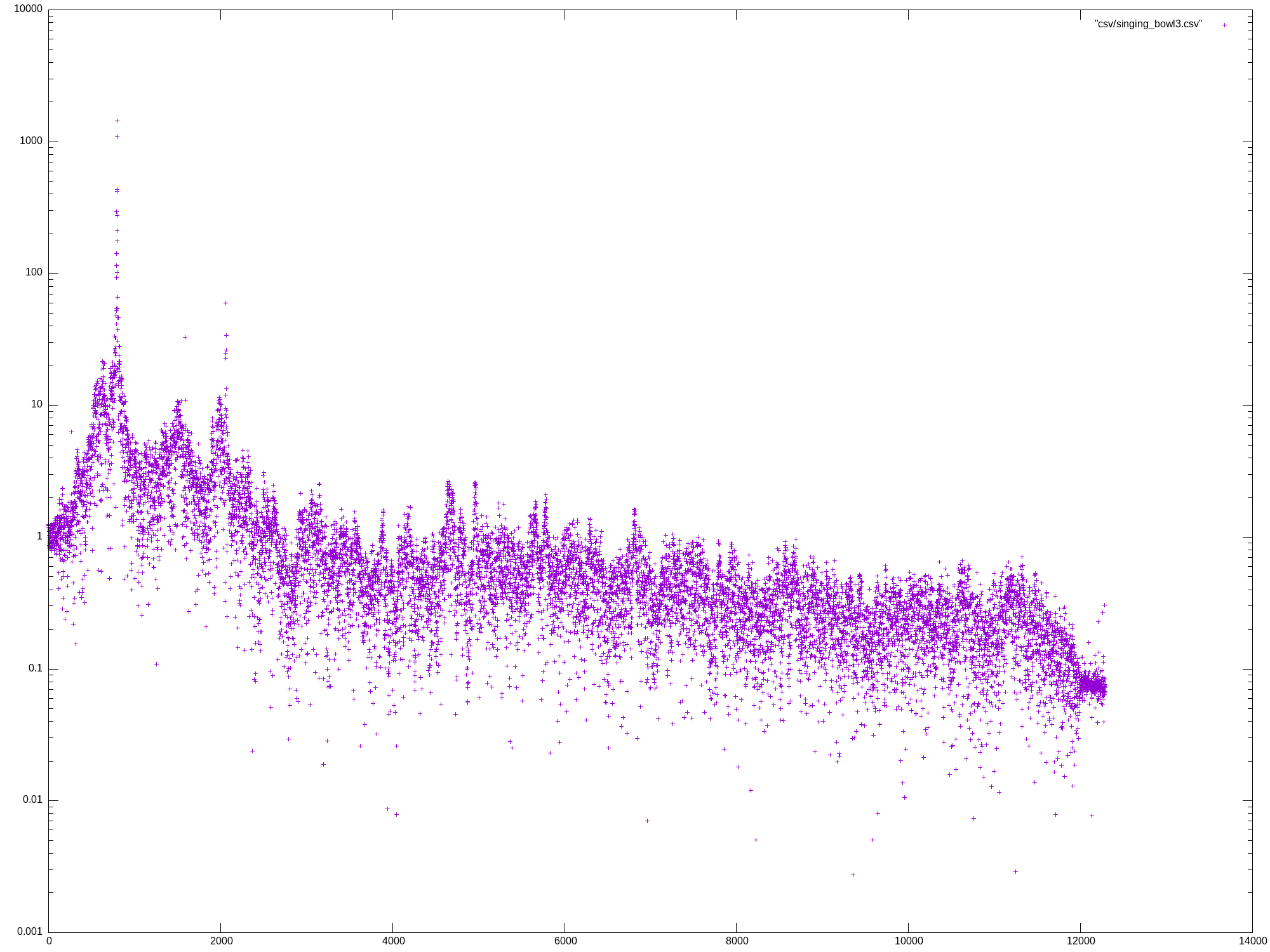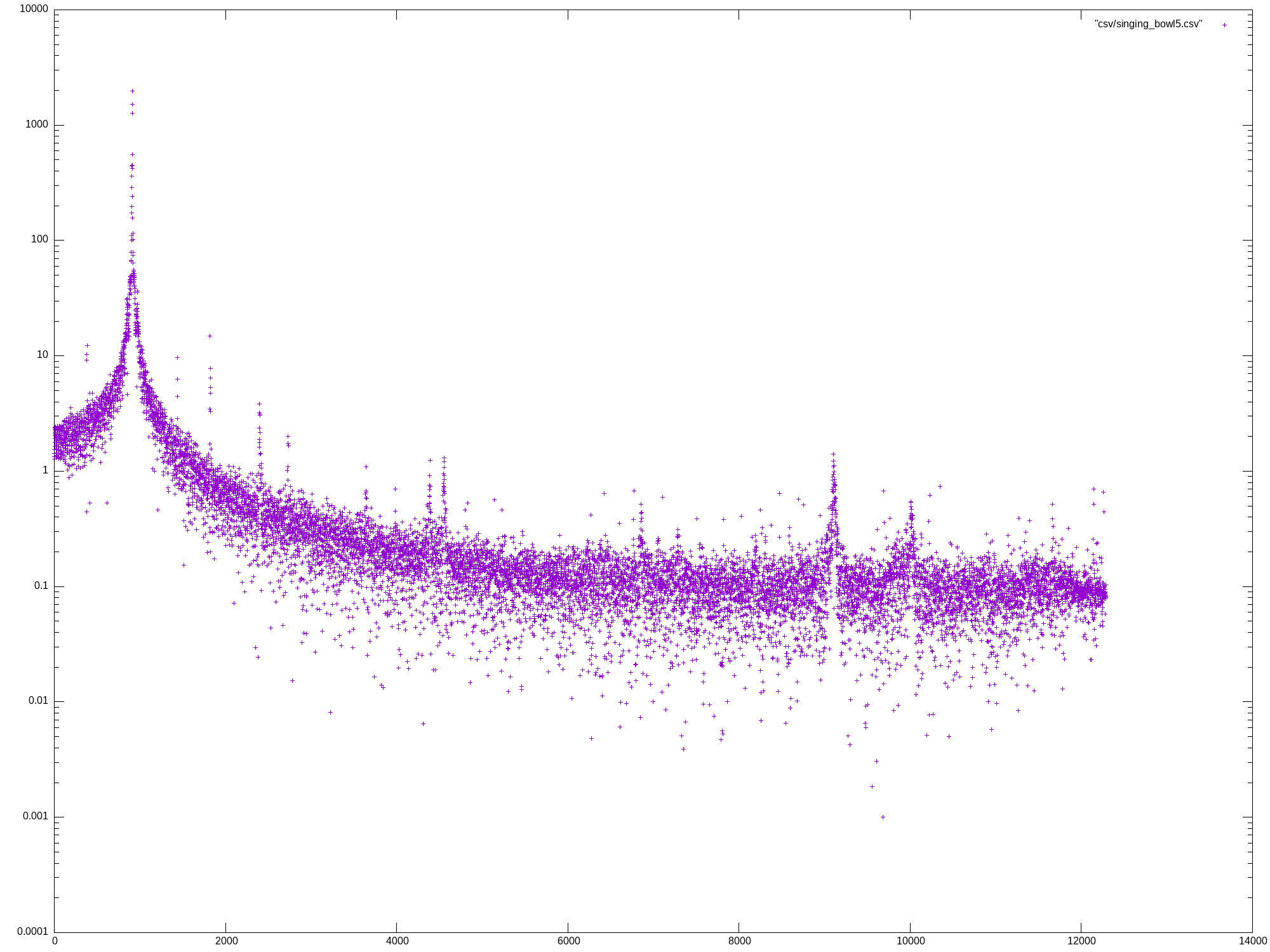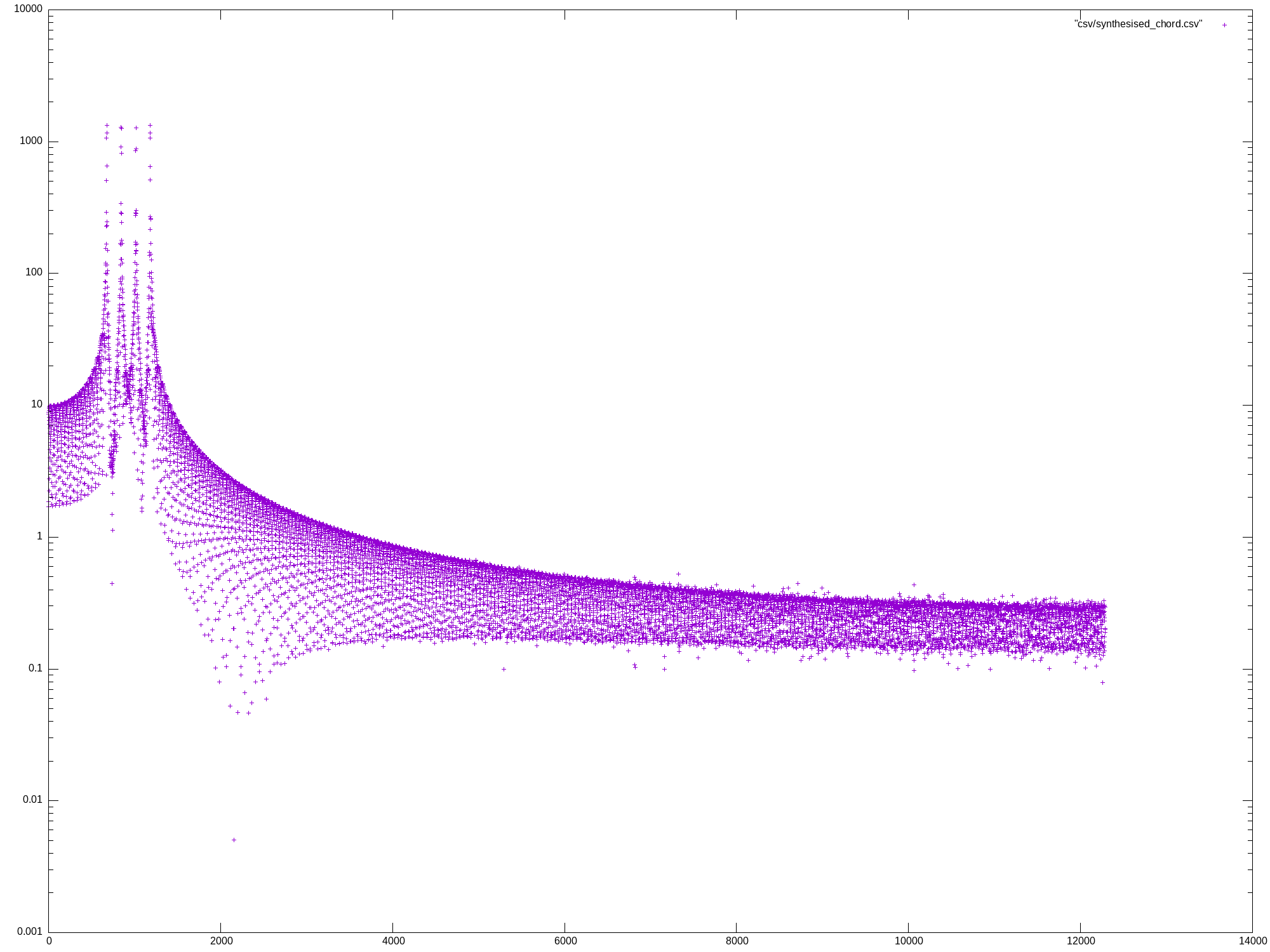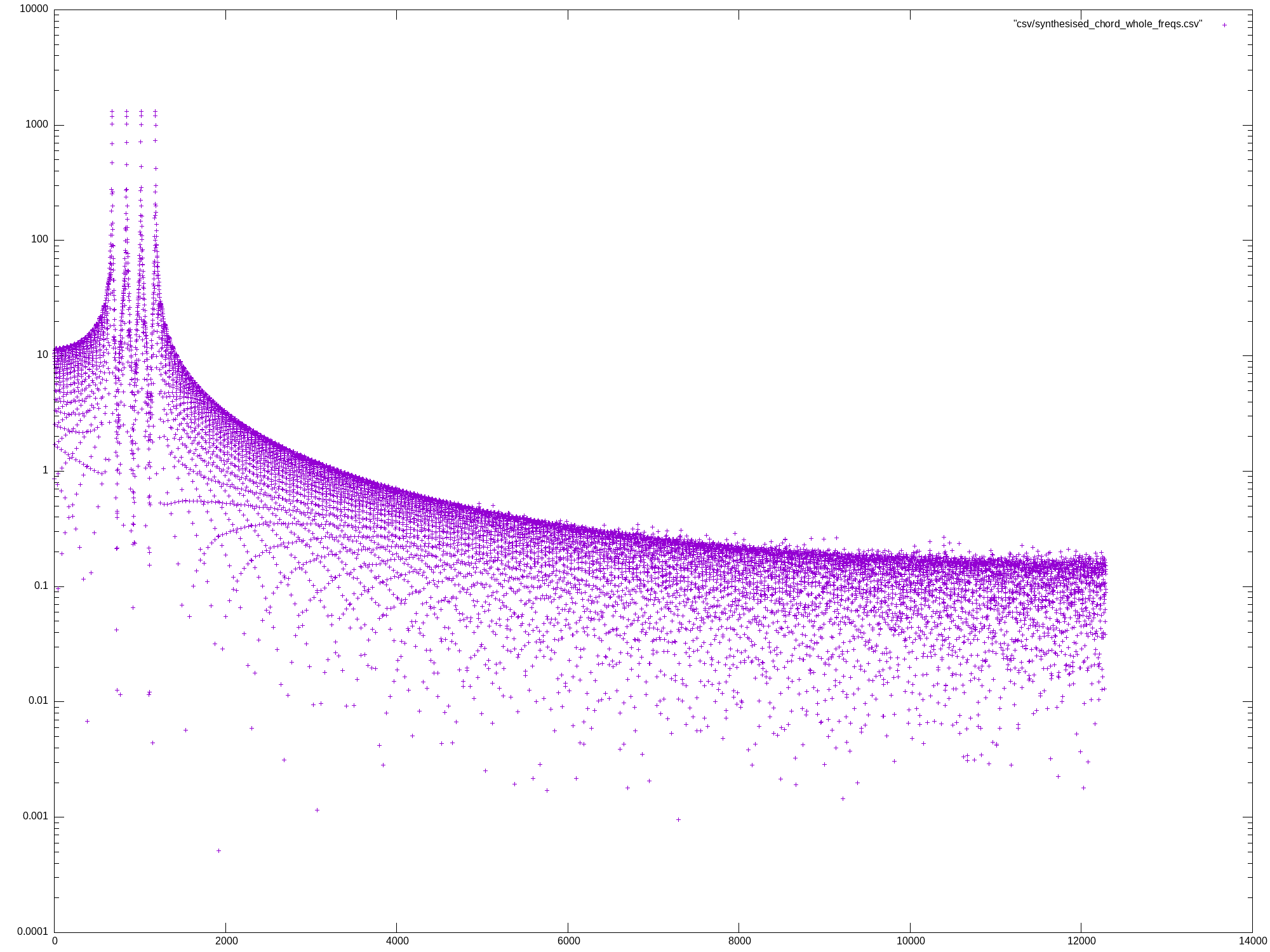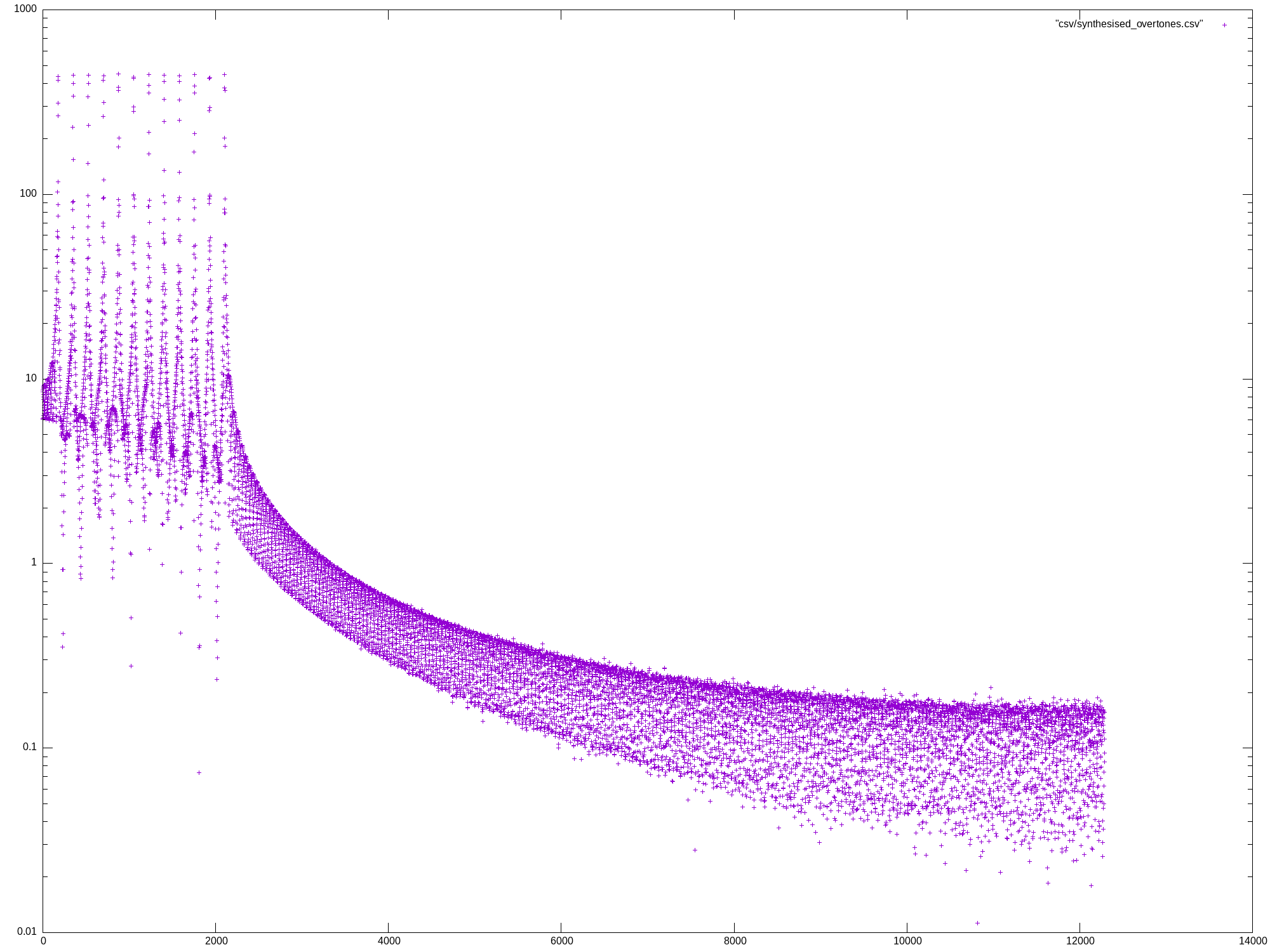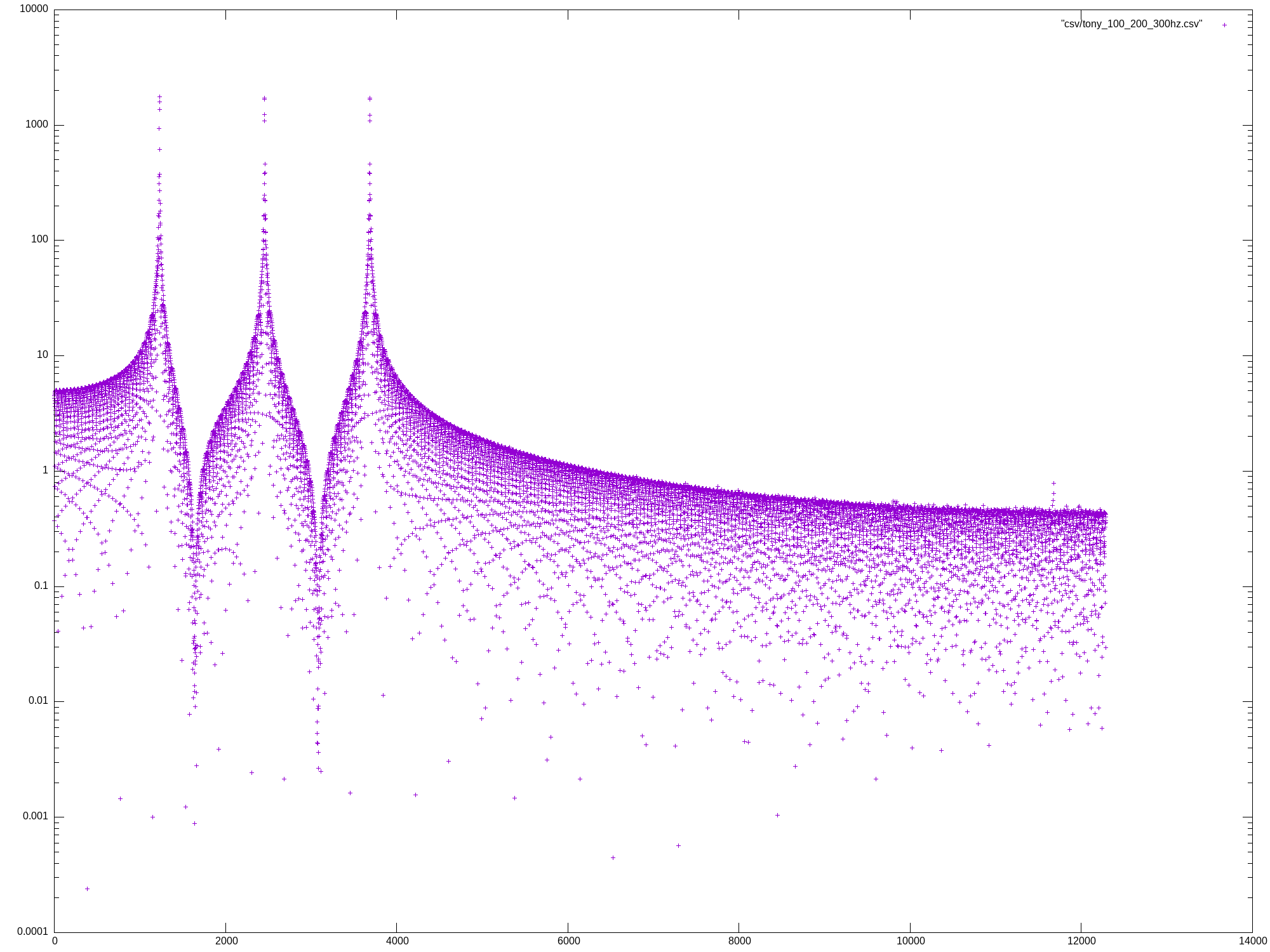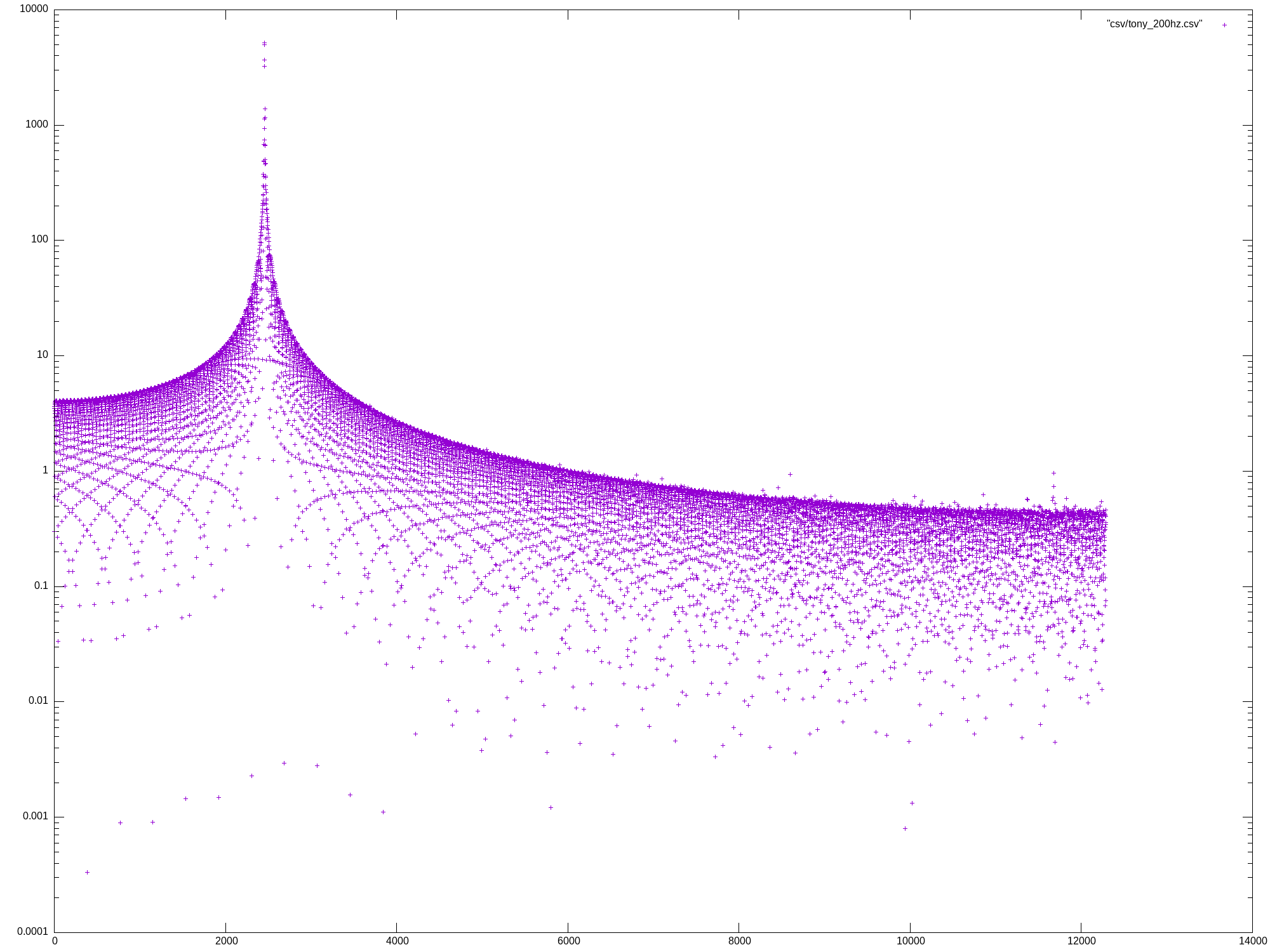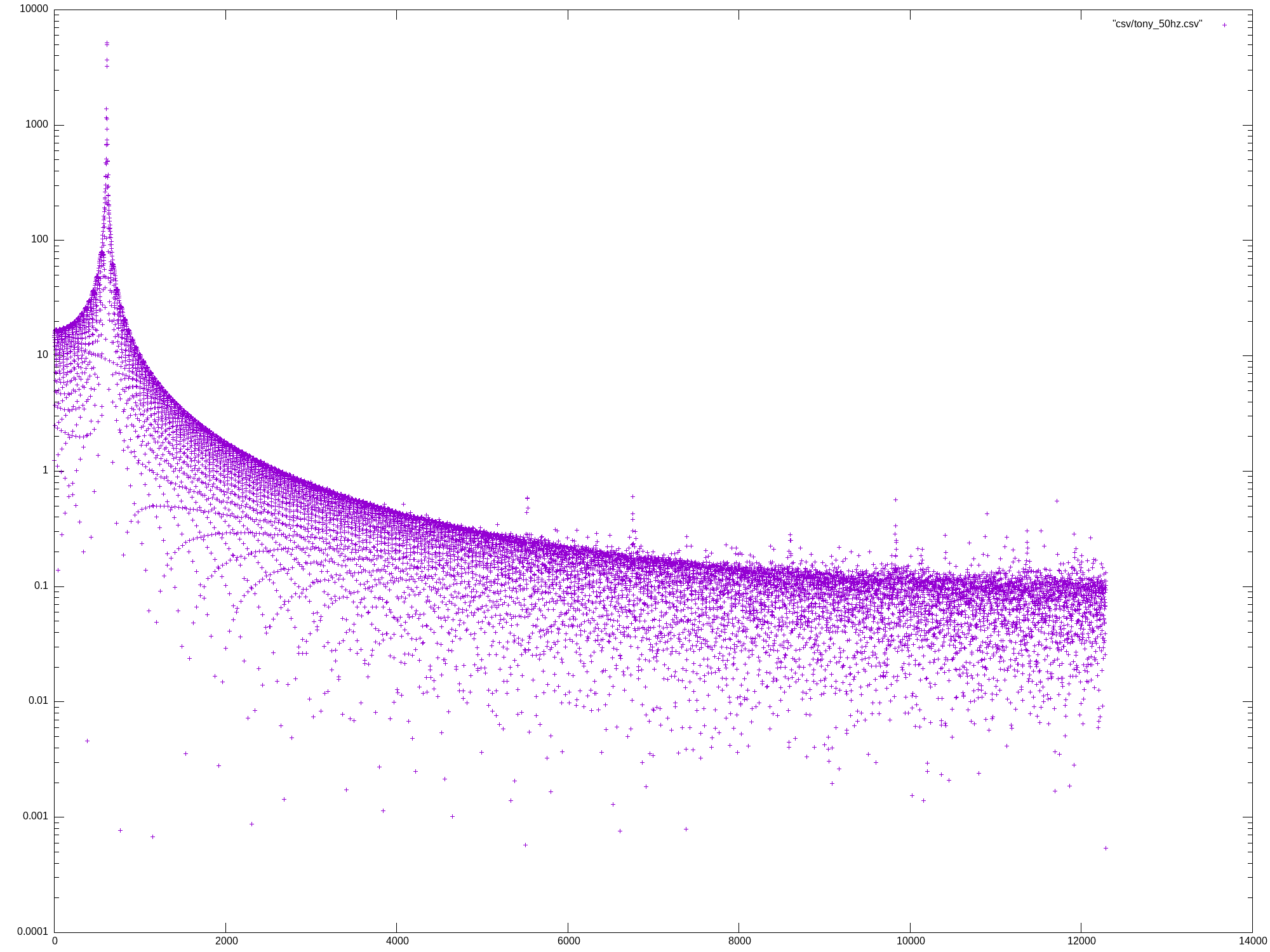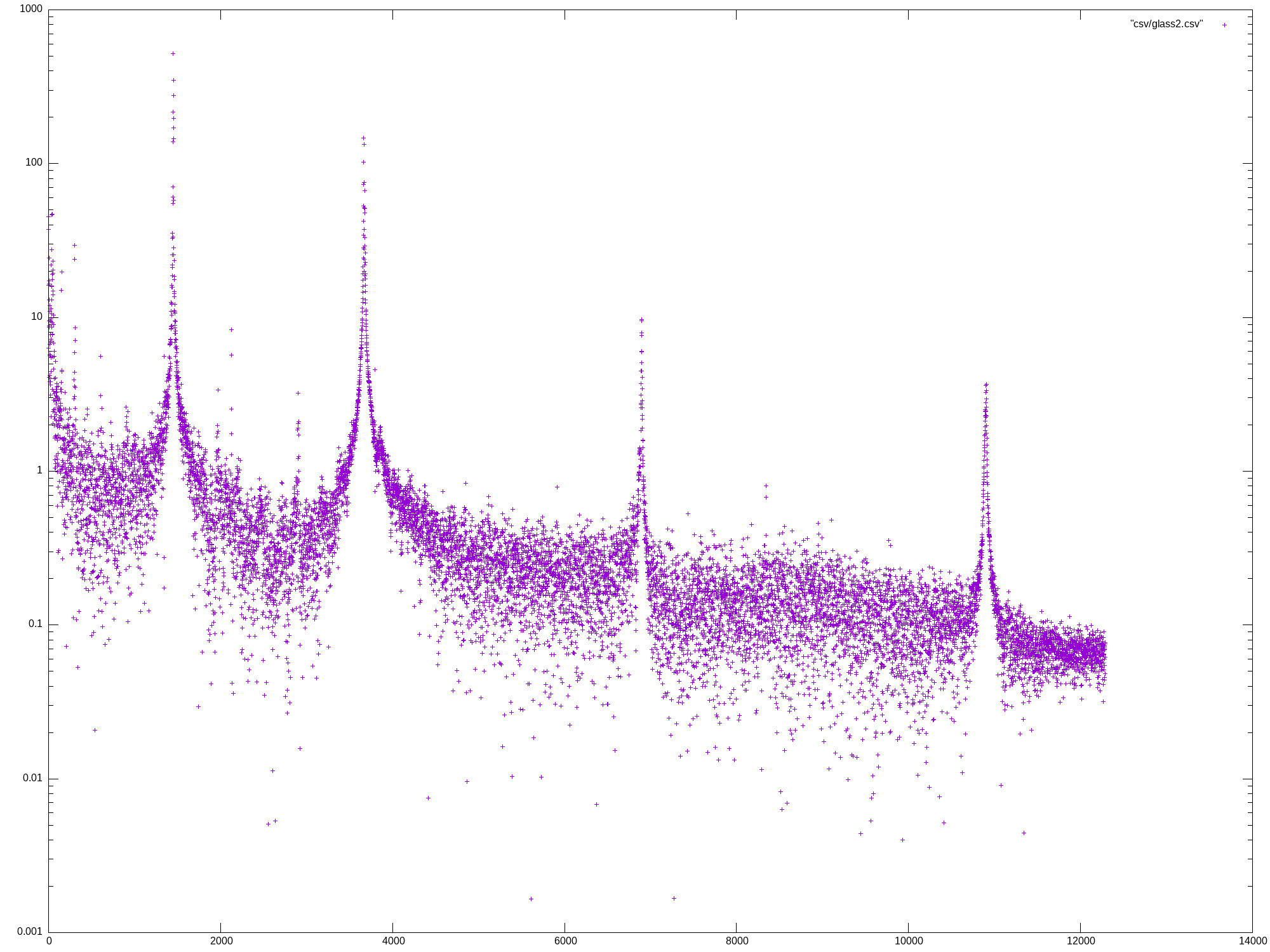
Mon May 27 13:07:04 UTC 2024
The aim of this project is to explore writing an FFT (really a DFT) from scratch and an opportunity to flex the latest C++. The aspiration is to keep up with realtime audio without depending on third-party libraries or firmware. See the pipeline for this repo.
The output of gprof is pretty unfriendly to parse for a
person, but piping it through gprof2dot is much
clearer.

Just for fun – and to remove the dependency on gtest – I’ve done all unit testing using static assertions. But I am still using Google Benchmark.
g++ over clang++-Ofastfloat instead of double (also lets you fit
a larger twiddle matrix in memory)Performance of a 16-core Google Cloud VM with 62GB of RAM:
#include "benchmark/benchmark.h"
#include <print>
#include <algorithm>
#include <array>
#include <assert.h>
#include <bits/chrono.h>
#include <cassert>
#include <chrono>
#include <cmath>
#include <complex>
#include <concepts>
#include <execution>
#include <filesystem>
#include <fstream>
#include <iterator>
#include <map>
#include <numbers>
#include <numeric>
#include <ranges>
#include <string>
#include <thread>
#include <type_traits>
#include <variant>
#include <vector>
/// The number of bins of the DFT is fixed at compile time. However, it's used
/// in two contexts -- to define the size of containers, and in complex number
/// calculations -- so multiple versions can be instantiated at compile time to
/// avoid conversion at run time.
template <class T> constexpr T bins = T{24'576};
/// The most computationally expensive part of this process is the exponent
/// calculation below, which must be repeated across all samples for every DFT
/// bin. However, there's nothing stopping us doing this up front as it doesn't
/// change.
///
/// "(n^2) is the sweet spot of badly scaling algorithms: fast enough to make it
/// into production, but slow enough to make things fall down once it gets
/// there."
/// -- Bruce Dawson
/// Warn the compiler that this routine is going to make your computer hot. It
/// would be nice if this could be done at compile time but it's just too darn
/// large. And annoyingly std::exp is not constexpr until C++26
template <typename T> [[gnu::hot]] auto generate_twiddle_matrix() {
static_assert(std::is_floating_point_v<T>);
// Initialise matrix
using row_t = std::vector<std::complex<T>>;
const auto row = row_t(bins<size_t>);
auto matrix = std::vector<row_t>(bins<size_t> / 2, row);
// Create indices to help parallelise the calculation
std::vector<size_t> ks(bins<size_t> / 2);
std::iota(begin(ks), end(ks), 0uz);
std::vector<size_t> ns(bins<size_t>);
std::iota(begin(ns), end(ns), 0uz);
// Populate and return matrix
std::for_each(
std::execution::par, begin(ks), end(ks), [&](const auto k) {
for (const auto n : ns)
matrix[k][n] = std::exp(T(k) * T(n) * std::complex<T>{0.0f, 2.0f} *
std::numbers::pi_v<T> / bins<T>);
});
return matrix;
}
void BM_generate_twiddle_matrix_float(benchmark::State &state) {
for (auto _ : state)
benchmark::DoNotOptimize(generate_twiddle_matrix<float>());
}
BENCHMARK(BM_generate_twiddle_matrix_float);
/// Conversion from degrees to radians
constexpr auto deg2rad(const std::floating_point auto degrees) {
using T = std::decay_t<decltype(degrees)>;
return std::numbers::pi_v<T> * degrees / T{180.0f};
}
static_assert(std::is_same_v<decltype(deg2rad(0.0)), double>);
static_assert(std::is_same_v<decltype(deg2rad(0.0f)), float>);
static_assert(deg2rad(0.1) > 0.0);
static_assert(deg2rad(0.1f) > 0.0f);
static_assert(deg2rad(91.0) > std::numbers::pi_v<double> / 2.0);
static_assert(deg2rad(181.0) > std::numbers::pi_v<double>);
static_assert(deg2rad(181.0f) > std::numbers::pi_v<float>);
static_assert(deg2rad(361.0) > std::numbers::pi_v<double> * 2.0);
void BM_deg2rad(benchmark::State &state) {
for (auto _ : state)
benchmark::DoNotOptimize(deg2rad(180.0));
}
BENCHMARK(BM_deg2rad);
/// Generate a clean sine wave to play with
constexpr auto generate_sine_wave(const std::floating_point auto frequency) {
using T = std::decay_t<decltype(frequency)>;
assert(frequency > T{});
// Initialise a container with the element index
std::array<T, bins<size_t>> samples;
// Populate samples
for (auto i = 0uz; i < std::size(samples); ++i) {
const auto x = static_cast<T>(i);
samples[i] = std::sin(frequency * deg2rad(x));
}
return samples;
}
static_assert(generate_sine_wave(440.0f)[1] > 0.0f);
static_assert(std::size(generate_sine_wave(440.0f)) == bins<size_t>);
void BM_generate_sine_wave_float(benchmark::State &state) {
for (auto _ : state) {
const auto samples = generate_sine_wave(440.0f);
benchmark::DoNotOptimize(samples);
}
}
BENCHMARK(BM_generate_sine_wave_float);
void BM_generate_sine_wave_double(benchmark::State &state) {
for (auto _ : state) {
const auto samples = generate_sine_wave(440.0);
benchmark::DoNotOptimize(samples);
}
}
BENCHMARK(BM_generate_sine_wave_double);
void BM_generate_sine_wave_long_double(benchmark::State &state) {
for (auto _ : state) {
const auto samples = generate_sine_wave(440.0);
benchmark::DoNotOptimize(samples);
}
}
BENCHMARK(BM_generate_sine_wave_long_double);
/// Get the twiddle for a given pair of indices, note the matrix is initialise
/// on first call
template <typename T> struct twiddle_t {
constexpr auto operator[](size_t x, size_t y) const {
assert(x < bins<size_t> / 2);
assert(y < bins<size_t>);
static const auto matrix = generate_twiddle_matrix<T>();
return matrix[x][y];
}
};
/// Calculate the sum of all responses for this frequency bin
auto response(const auto &samples, const size_t x) {
assert(std::size(samples) == bins<size_t>);
assert(x < bins<size_t> / 2);
using T = std::decay_t<decltype(samples)>::value_type;
// Initialise twiddle matrix
static const twiddle_t<T> twiddle;
// I wouldn't normally advocate this old-school for-loop style but it's the
// clearest way to get the sample index into the twiddle calculation
auto result = std::complex<T>{};
// Operator overload allows multidimensional array access
for (const auto &[y, sample] : std::views::enumerate(samples))
result += sample * twiddle[x, y];
return result;
}
void BM_response(benchmark::State &state) {
constexpr auto samples = generate_sine_wave(440.0f);
for (auto _ : state) {
const auto r = response(samples, 1uz);
benchmark::DoNotOptimize(r);
}
}
BENCHMARK(BM_response);
/// I originally wrote this whole process as one large routine but breaking it
/// up does make the profile results clearer. It's also easier to unit test,
/// benchmark and refactor.
/// Calculate the response across the samples in each bin of the DFT
auto analyse(const auto &samples) {
assert(std::size(samples) == bins<size_t>);
// The incoming floating point type is unwieldy so let's define a type alias
using T = std::decay_t<decltype(samples)>::value_type;
// Initialise the results container with the index, this allows us to
// parallelise the calculation without keeping track of the current element's
// index
std::vector<T> dft(bins<size_t> / 2);
std::iota(begin(dft), end(dft), T{});
// Remember you must link against tbb for any of this execution policy
// stuff or it will quietly execute serially
std::for_each(std::execution::par, begin(dft), end(dft), [&](T &bin) {
// Convert to a real by scaling the absolute value by the number of bins
bin = std::abs(response(samples, static_cast<size_t>(bin))) / bins<T>;
});
return dft;
}
void BM_analyse_float(benchmark::State &state) {
constexpr auto samples = generate_sine_wave(2000.0f);
for (auto _ : state)
benchmark::DoNotOptimize(analyse(samples));
}
BENCHMARK(BM_analyse_float);
/// Dump the DFT results as a CSV for plotting
void write_csv(const auto dft, const std::string stem) {
assert(not std::empty(stem));
assert(std::size(dft) == bins<size_t> / 2);
using T = decltype(dft)::value_type;
const std::string file_name = "../csv/" + stem + ".csv";
if (std::ofstream csv_file{file_name}; csv_file.good())
std::ranges::copy(dft, std::ostream_iterator<T>(csv_file, "
"));
}
/// Write the summary string to file
void write_summary(const auto stats) {
assert(not std::empty(stats));
std::ofstream out{"summary.txt"};
for (const auto &[key, value] : stats) {
out << "- ";
if (std::holds_alternative<size_t>(value))
out << std::get<size_t>(value);
if (std::holds_alternative<float>(value))
out << std::get<float>(value);
if (std::holds_alternative<double>(value))
out << std::get<double>(value);
out << " " << key << "
";
}
}
/// Read a WAV file and return the samples as a container of floating points
template <typename T> auto read_wav(const std::string file_name) {
assert(file_name.ends_with(".wav"));
// Structure of a WAV header
struct {
uint32_t riff_id_;
uint32_t riff_size_;
uint32_t wave_tag_;
uint32_t format_id_;
uint32_t format_size_;
uint32_t format_tag_ : 16;
uint32_t channels_ : 16;
uint32_t sample_rate_;
uint32_t bytes_per_second_;
uint32_t block_align_ : 16;
uint32_t bit_depth_ : 16;
uint32_t data_id_;
uint32_t data_size_;
} header;
assert(sizeof header == 44uz);
// Read WAV header
std::ifstream audio{file_name};
audio.read(reinterpret_cast<char *>(&header), sizeof header);
// Read a block of raw data to analyse
std::vector<short> raw(bins<size_t>);
const size_t raw_bytes = std::size(raw) * sizeof(decltype(raw)::value_type);
audio.read(reinterpret_cast<char *>(raw.data()), raw_bytes);
// Convert to target type
return std::vector<T>{raw.cbegin(), raw.cend()};
}
void BM_read_wav_float(benchmark::State &state) {
for (auto _ : state)
benchmark::DoNotOptimize(read_wav<float>("../wav/440hz.wav"));
}
BENCHMARK(BM_read_wav_float);
void BM_read_wav_double(benchmark::State &state) {
for (auto _ : state)
benchmark::DoNotOptimize(read_wav<double>("../wav/440hz.wav"));
}
BENCHMARK(BM_read_wav_double);
/// Run DFT for all WAV files
template <typename T> void run_dft() {
// Get list of files to process
const std::filesystem::path p{"../wav/"};
const std::vector files(std::filesystem::directory_iterator{p}, {});
assert(not std::empty(files));
// Start timer for main process
using namespace std::chrono;
const auto start_timing = high_resolution_clock::now();
// Calculate DFT for each file
std::println("Processing {} files", std::size(files));
for (const auto &file : files) {
// Skip any unsupported file types
if (not(file.path().extension() == ".wav"))
continue;
const std::string file_name = file.path();
std::println(" {}", file_name);
// Get samples for a WAV file and analyse
const auto samples = read_wav<T>(file_name);
const auto dft = analyse(samples);
assert(std::size(dft) == bins<size_t> / 2);
// Get the base file name and write DFT to disk
write_csv(dft, file.path().stem());
}
// Create summary
const auto end_timing = high_resolution_clock::now();
const auto diff = duration_cast<microseconds>(end_timing - start_timing);
const auto samples_per_second =
1e6f * static_cast<float>(std::size(files) * bins<size_t>) /
static_cast<float>(diff.count());
std::map<std::string, std::variant<size_t, float, double>> stats;
stats["cores"] = std::thread::hardware_concurrency();
stats["files"] = std::size(files);
stats["GiB twiddle matrix"] =
bins<size_t> * (bins<size_t> / 2) * sizeof(T) / std::pow(2.0f, 30);
stats["s analysis duration"] = static_cast<float>(diff.count()) / 1e6f;
stats["samples per second"] =
1e6f * static_cast<float>(std::size(files) * bins<size_t>) /
static_cast<float>(diff.count());
stats["DFT bins"] = bins<size_t>;
stats["x speed up"] = samples_per_second / bins<T>;
write_summary(stats);
}
int main(int argc, char **argv) {
::benchmark::Initialize(&argc, argv);
::benchmark::RunSpecifiedBenchmarks();
run_dft<float>();
}